Optimizing SlimPajama dataset pre-processing#
Overview#
The slimpajama directory in Cerebras Model Zoo contains scripts to pre-process SlimPajama end-to-end. Our dataset is publicly available on HuggingFace: SlimPajama-627B and you can download it under Apache 2.0 license.
Data source |
Tokens |
Open Source |
Curated Data Sources |
Deduplication Level |
|---|---|---|---|---|
SlimPajama |
627B |
Yes |
Yes |
Extensive |
RedPajama |
1.21T |
Yes |
Yes |
Partial |
RefinedWeb-600B |
600B |
Yes |
No |
Extensive |
RefinedWeb-5T |
5T |
No |
No |
Extensive |
LLaMA |
1.4T |
No |
Yes |
Partial |
MPT |
1T |
No |
Yes |
Unknown |
MassiveText |
1.4T |
No |
Yes |
Extensive |
Table 1: Comparison of dataset features
Environment Setup#
The file requirements.txt contains the pre-requisites that are needed to enable a clean run of the scripts. Below is how to setup the environment:
$ virtualenv slim_pajama_env
$ source slim_pajama_env/bin/activate
(slim_pajama_venv) $ pip install -r requirements.txt
To Replicate SlimPajama#
If you wish to reproduce our dataset, you can either follow our Step-by-step Guide or run the following command:
(slim_pajama_venv) $ python main.py <prefix_path>/RedPajama/
It took ~2.5 days to process the 1.21T token RedPajama dataset on a machine with 64 CPU cores, but note that using main.py will take longer as it doesn’t parallelize some steps across the data chunks. The highest RAM consumption that we observed was ~1.4TB.
Step-by-step Guide#
Our pre-processing pipeline consists of multiple stages such as NFC normalization, cleaning, deduplication, document interleaving, document shuffling, split into train and holdout sets, deduplication of train set against holdout. All these steps are presented in the diagram below. Additional steps such as tokenization, sequence packing and sequence-level shuffling can be performed using our scripts located at hdf5_preprocessing and hdf5_shuffling. All steps here assume that the whole dataset cannot fit in the available RAM and distributed across multiple processes. We are welcoming any additional datasets preparation steps or suggestions on how to make this even more efficient on the large scale datasets!
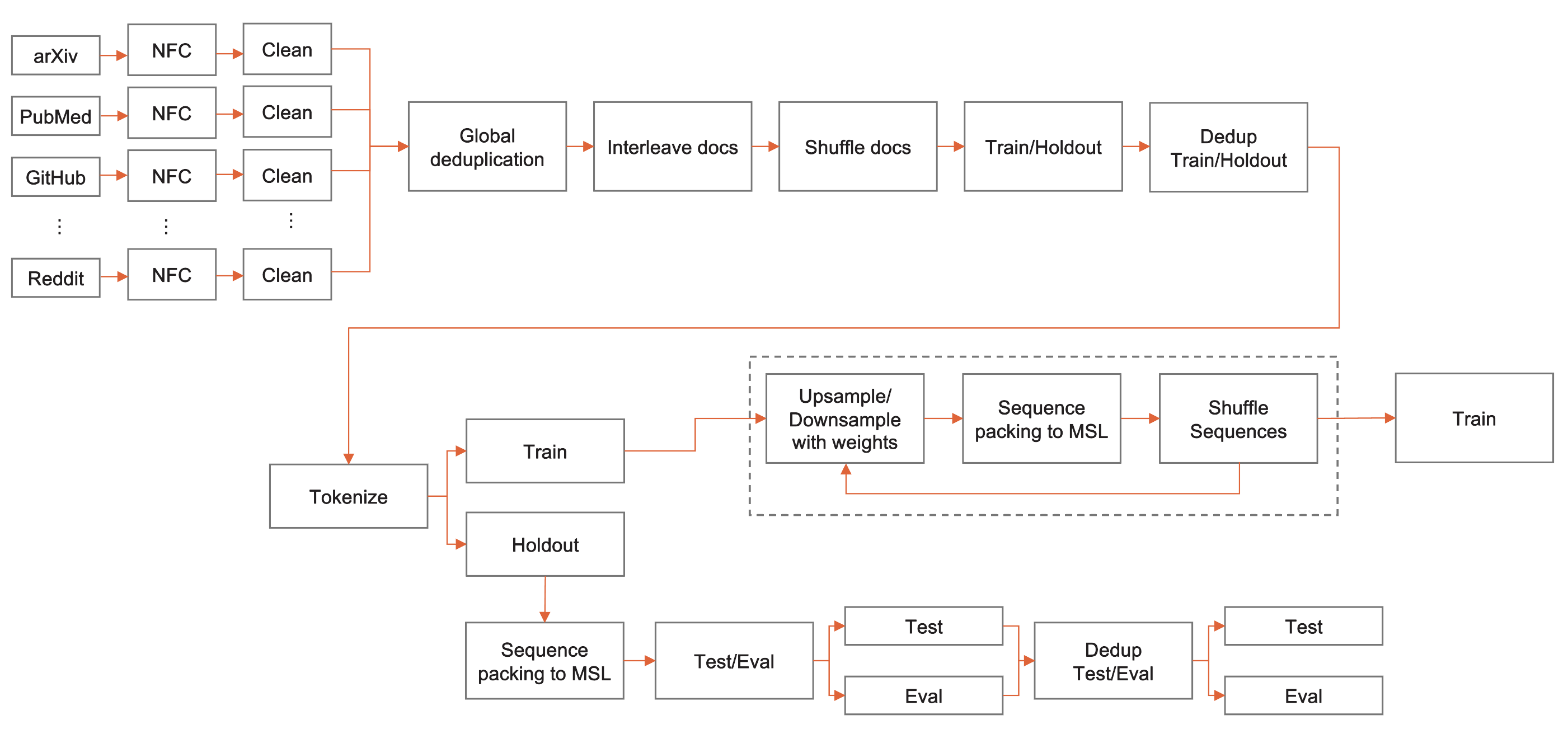
SlimPajama pre-processing pipeline#
Note
Every step produces a transformed version of the dataset. Be sure to provision enough disk space or actively delete intermediate versions!
Step 1: NFC Normalization#
To remove non unicode characters we apply NFC normalization so that letters followed by combining characters become single combined characters (following GPT-2).
Here is an example command to run NFC normalization:
(slim_pajama_venv) $ python preprocessing/normalize_text.py \
--data_dir <prefix_path>/RedPajama/arxiv/ \
--target_dir <prefix_path>/RedPajama_norm/arxiv/
To reduce the total processing time, multiple jobs can be run for each corpus in parallel. For example, distribute the data files into multiple sub-directories, then replace <prefix_path>/RedPajama_norm/arxiv/ with <prefix_path>/RedPajama_norm/arxiv/<subfolder> instead.
NOTE: for dataset files in
.jsonl.zstformat (like common_crawl), please include the flag--zst.
Step 2: Filter Short Documents#
We found 1.86% of RedPajama’s source documents contained improperly downloaded or low-length contents that we did not consider useful to include in the training data. After removing punctuation, space symbols, newlines and tabs, we filtered out documents with less than 200 characters.
Here is an example command to find documents that need to be filtered out:
(slim_pajama_venv) $ python preprocessing/filter.py \
<prefix_path>/RedPajama_norm/<dataset_name>/ \
<prefix_path>/RedPajama_filtered.pickle \
<n_docs> \
<dataset_name> \
<threshold>
Step 3: Deduplication#
To perform global dataset deduplication (within and between corpora), we used the datasketch library and applied further optimizations to reduce memory consumption and increase parallelism. Our implementation is using producer-consumer schema in order to parallelize I/O operations that dominate our runtime. In addition, we applied code changes to reduce the memory utilization by keeping only one document per set of duplicates in memory. To the best of our knowledge this the first open-sourced deduplication library written in Python that can process Trillion token datasets. The deduplication process includes multiple stages such as building MinHashLSH index, performing querying into the index to locate duplicates, building a graph representation to locate connected components with duplicates and finally filtering duplicates in each component. Below you can find commands to reproduce each step in the pipeline as well as parameters that we pre-processed SlimPajama dataset with.
Step 3.1: MinHash Generation#
MinHash generation can be a very slow process. We recommend running it separately before creating a MinHashLSH index. To calculate MinHash object for each document, we strip, lowercase, remove punctuation, consecutive spaces, newlines and tabs from each document. Afterwards, we construct a list of 13-grams that are later used as features to create a document signature to add into MinHashLSH index. More details about MinHash can be found at Identifying and Filtering Near-Duplicate Documents.
Here is an example command to run MinHash generation:
(slim_pajama_venv) $ python dedup/to_hash.py \
<dataset_name> \
<prefix_path>/RedPajama_norm/<dataset_name>/ \
<prefix_path>/RedPajama_minhash/<dataset_name>/ \
<n_docs> \
<iter> \
<index_start> \
<index_end> \
-w <ngram_size> \
-k <buffer_size>
Similarly to NFC normalization, you can run multiple jobs in parallel for each corpus if you wish.
Step 3.2: Duplicate Pairs Generation#
In this step, we build a MinHashLSH index and query it to locate near duplicates Chapter 3, Mining of Massive Datasets. We are using Jaccard similarity threshold of 0.8
to determine whether a pair of documents should be considered as a duplicate. Our implementation is using --range and --bands arguments that can be
calculated with datasketch/lsh.py given a Jaccard threshold. We find
aggressive deduplication the most efficient, but you can change the parameters below in order to reduce the amount of filtered content.
(slim_pajama_venv) $ python dedup/generate_duplicate_pairs.py \
--input_dir <prefix_path>/RedPajama_minhash/ \
--out_file <prefix_path>/redpj_duplicates/duplicate_pairs.txt \
--range <range> \
--bands <bands> \
--processes <n_processes>
Note: This step consumed 1.4TB of memory for the 1.21T token RedPajama dataset. If you cannot access an instance with enough memory for your use case, this step will need to be split up further. We experimented with splitting the LSH object into multiple buckets to reduce memory consumption. This strategy should be easy to implement given the organization of our scripts.
NOTE: total number of processes that will be created is
<n_processes>+<bands>
Step 3.3: Duplicate Graph Construction & Search for Connected Components#
After locating duplicate pairs, we need to find connected components containing documents that are duplicates with each other. To make it more illustrative, consider
these pairs: (A, B), (A, C), (A, E). We are going to form a cluster of (A, B, C, E) and keep only one document from the component.
We evaluated the performance and memory consumption of networkx, graphtool, and networkit. networkit offered most efficient implementation as it is designed to work with large graphs and features great parallelism.
Below you can find an example command how to construct a graph from documents pairs:
(slim_pajama_venv) $ python dedup/generate_connected_components.py \
--input_dir <prefix_path>/redpj_duplicates \
--out_file <prefix_path>/redpj_duplicates/connected_components.pickle
Step 3.4: Generate Final List of Duplicates#
Finally, we need to process the connected components and create a lookup table so we can filter out duplicates later.
Below you can find an example command on how to generate a list of duplicates:
(slim_pajama_venv) $ python dedup/generate_duplicates_dict.py \
--input_file <prefix_path>/redpj_duplicates/connected_components.pickle \
--out_file <prefix_path>/redpj_duplicates/duplicates.pickle
Step 4: Interleave & Shuffle#
Before we can train a model on the multi-sourced dataset we need to mix the sources together with specified weights. For SlimPajama we sample 1 epoch from each corpus, but you can easily update the sampling weights located in preprocessing/datasets.py. This stage is also I/O bound and our implementation follows a producer-consumer schema.
An example command on how to run this step is provided below:
(slim_pajama_venv) $ python preprocessing/shuffle_holdout.py pass1 \
--input_dir <prefix_path>/RedPajama_norm/ \
--duplicates <prefix_path>/redpj_duplicates/duplicates.pickle \
--short_docs <prefix_path>/RedPajama_filtered.pickle \
--out_dir <prefix_path>/SlimPajama/pass1
In addition to mixing the sources, we also perform shuffling to avoid any ordering bias. We follow the-pile 2-pass shuffling algorithm implementation how-to-shuffle-a-big-dataset and adopt it SlimPajama.
Step 5: Split Dataset into Train and Holdout#
During this step we finish 2-pass shuffling and create a holdout set. To speed up the process, we split the source data into chunks and process them in parallel. An example command is provided below:
for j in {1..20}
do
python preprocessing/shuffle_holdout.py pass2 "$((j-1))" "$j" "$j" --input_dir <prefix_path>/SlimPajama/pass1 --train_dir <prefix_path>/SlimPajama/train --holdout_dir <prefix_path>/SlimPajama/holdout > $j.log 2>&1 &
done
Step 6: Deduplicate Train against Holdout#
The final step is to make sure that there is no overlap between the train and holdout sets. This is important to ensure unbiased decision regarding your model’s behaviour. To decontaminate our training set, we apply the SHA256 hashing algorithm to find exact matches between train and holdout sets. Then we filter the exact matches from the training set. Example command is provided below:
python dedup/dedup_train.py 1 --src_dir <prefix_path>/SlimPajama/train --tgt_dir <prefix_path>/SlimPajama/holdout --out_dir <prefix_path>/SlimPajama/train_deduped
for j in {2..20}
do
python dedup/dedup_train.py "$j" --src_dir <prefix_path>/SlimPajama/train --tgt_dir <prefix_path>/SlimPajama/holdout --out_dir <prefix_path>/SlimPajama/train_deduped > $j.log 2>&1 &
done
Steps 5 & 6 can be further applied to split holdout set into test and eval. For SlimPajama, decontaminated train, validation, and test sets are already available in our HuggingFace repo: SlimPajama-627B.
Contributing to SlimPajama#
We believe that open source diverse high-quality datasets are the key contributors towards successful training of LLM and further AI democratization. We are welcoming the community to contribute and expand our SlimPajama corpus with additional data sources. First thing to do is to open an issue. Your issue should include a description of the dataset, its size (bytes or tokens), what language(s) it is in, a link to the data, and any other relevant information. We are working on making the contribution process more streamlined, feel free to reach out to us via email to support@cerebras.net or join our discord to express your wish to contribute.
Future Work#
At Cerebras, we strive efficiency in every step in the pre-processing and model training pipeline. This is our first attempt to open-source a pre-processing pipeline for large datasets. We are working on making these scripts more generalizable and useful for any type of the datasets suitable for training ML models. We appreciate any feedback that you provide to improve this library!
Citation#
To cite our work please use:
@misc{cerebras2023slimpajama,
author = {Soboleva, Daria and Al-Khateeb, Faisal and Myers, Robert, Steeves, Jacob R and Hestness, Joel and Dey, Nolan},
title = {{SlimPajama: A 627B token cleaned and deduplicated version of RedPajama}},
month = June,
year = 2023,
howpublished = {\url{https://www.cerebras.net/blog/slimpajama-a-627b-token-cleaned-and-deduplicated-version-of-redpajama}},
url = {https://huggingface.co/datasets/cerebras/SlimPajama-627B},
}
Acknowledgement#
We’d like to thank Together, Ontocord.ai, ETH DS3Lab, AAI CERC Lab for creating the original RedPajama dataset and releasing it open source. This release was made possible with the support and collaboration of Opentensor. Easy cloud access to Cerebras systems is provided by our partner Cirrascale.